The Building Blocks of an Agent Memory System

The Building Blocks of an Agent Memory System
Most agent "memory" systems retrieve too much. They paste the last N turns into the context window, or they dump the top-K results from a vector search, and they hope the model finds the signal. The model usually does — but at 50× the token cost it should be paying.
The version I've been building, claude-memory, is designed around the opposite principle: surface a small, well-chosen index up front, and provide a deeper retrieval path the model can opt into when it actually needs detail. The intuition behind that design comes from a handful of recent papers, and each layer of the system can be traced back to a specific finding from that literature.
This post walks through those layers from the bottom up. By the end you should have the conceptual model: what an agent memory system is, what choices it has to make, and which trade-offs the literature is converging on. (Benchmarks of claude-memory itself are still TBD — what's documented here is the design and the reasoning, not measured wins over a baseline.)
The atomic unit: Elementary Discourse Units
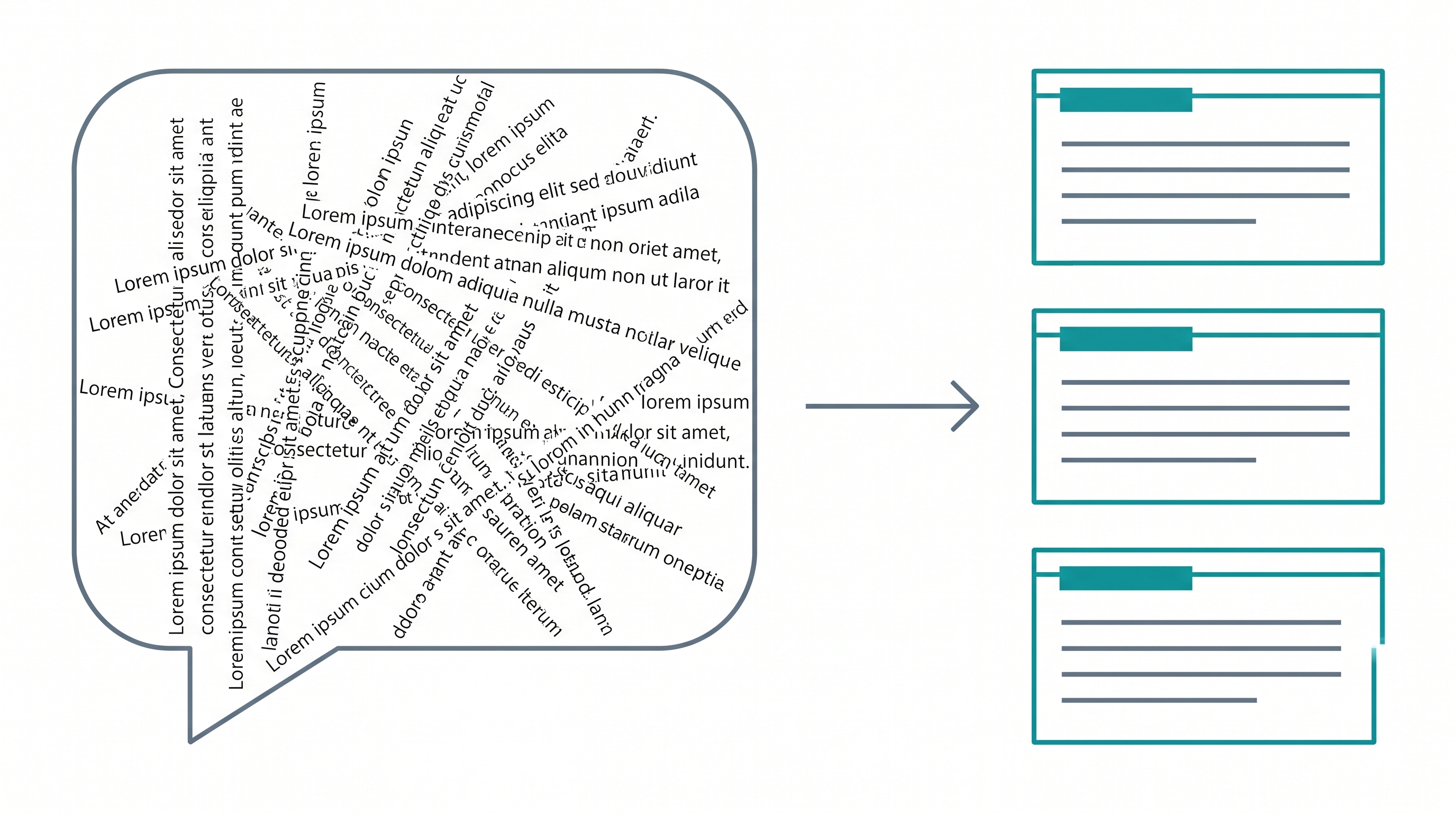
The first question is: what's the thing you store?
The naive answer is "the conversation." Save the transcript, search it later. This collapses immediately at scale — your queries match too coarsely, you retrieve too much, and the model loses the signal in the noise.
The next-best answer is "the turn." Each user message and each assistant response becomes a searchable unit. Better, but still wrong. A single assistant turn often covers five unrelated things. A single user turn often references context the model has to reconstruct ("yeah do that one"). Turn-level retrieval gives you fragments that aren't self-contained.
The right answer comes from EMem (Sun et al., arXiv:2511.17208) — "A Simple Yet Strong Baseline for Long-Term Conversational Memory." They decompose conversations into Elementary Discourse Units: atomic, self-contained facts. One EDU, one claim. Pronouns resolved, dates inferred, entity names included.
A turn that says
"Yeah, the one we tried last week — that worked. Let's do it again."
becomes EDUs like
"On 2026-04-12 the team tested the X approach and it succeeded. The plan is to repeat the X approach in the upcoming session."
Each EDU is searchable on its own. There's no "what was 'it'?" problem at retrieval time.
The benchmark numbers from EMem are striking: 738 tokens of EDU context returned per query, against 23,653 tokens for a full-context baseline — a 97% reduction — while beating the baseline on the LoCoMo benchmark (0.780 LLM-judge score, SOTA at publication). The decomposition step turns out to matter more than anything you do downstream.
So that's the atom. Everything else in the system is a choice about how to structure, retrieve, and surface these atoms.
Memory hierarchy: why flat trajectories
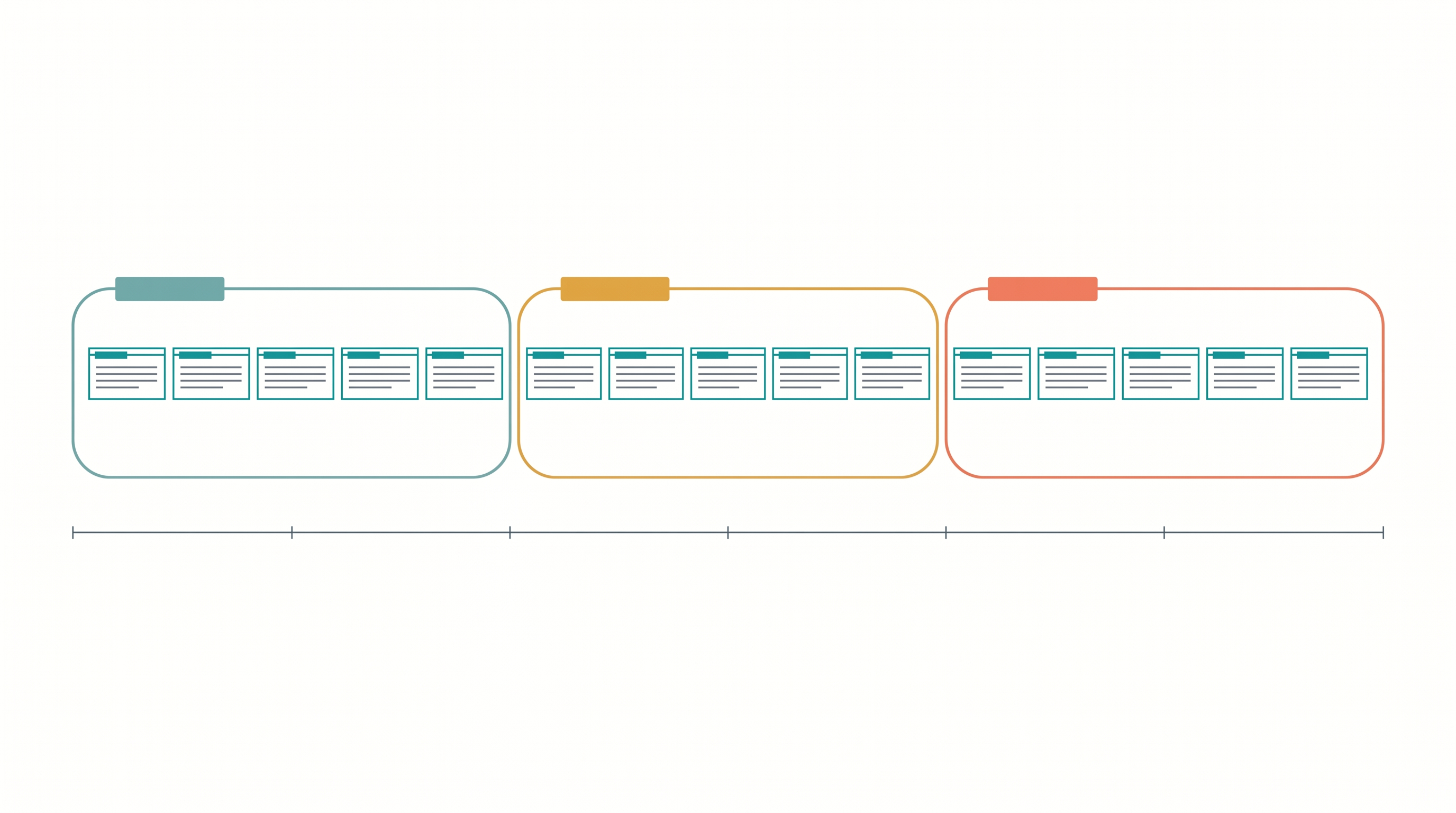
Once you have EDUs, the next question is: what shape does memory take?
The recent survey "Memory in the Age of AI Agents" (arXiv:2512.13564) catalogs the design space along three axes: Form (token-level vs. parametric), Function (factual vs. procedural vs. episodic), and Dynamics (how memories form, retrieve, and evolve). Within Form/token-level, the cataloged systems span a wide range:
- Flat lists of facts — every memory equal, retrieve by similarity (Memoria, A-Mem)
- Hierarchical summaries — facts roll up into chapter summaries which roll up into volume summaries
- Knowledge graphs — facts as nodes, relationships as edges, retrieval via traversal (HippoRAG, Generative Agents)
- Parametric memory — agents update weights from experience (severely under-explored, per the survey)
Each adds capability and cost. KGs let you do multi-hop reasoning but require entity linking, schema decisions, and PageRank-style retrieval. Hierarchical summaries let you skim before drilling, but the summary layer drifts from the source as conversations accumulate.
EMem's ablation already gave away the answer: EMem-without-graph nearly matches EMem-with-graph. The graph adds marginal value. The simplest shape — a flat collection of EDUs with one mid-level grouping — captures most of the win.
So claude-memory settles on the simplest shape that still preserves context: an ordered sequence of EDUs, partitioned into trajectories.
- EDUs are the storage and search unit — atomic facts, ordered by their position in the original conversation. This is what gets embedded and ranked.
- Trajectories are contiguous runs of EDUs covering a single topic — effectively, sub-conversations. A trajectory carries a 1-line summary and a few keywords, and that's the full extent of its metadata.
No tree, no graph, no summary tower. A trajectory is just a topic boundary on a flat sequence.
The split between "what you store/search" and "what you return" matters. At retrieval time you don't return individual EDUs — you return whole trajectories. A hit on any single EDU pulls back the entire sub-conversation that EDU belongs to, plus the tail of the trajectory before it and the head of the trajectory after it (so the model sees the lead-in and lead-out — what the conversation was just about, and where it went next). Multiple hits in the same session that overlap get re-stitched into one continuous block.
This is the "atomic ranking, contiguous return" pattern: EDUs give you fine-grained matching; trajectories give you coherent context to actually read. Structure is added at retrieval time by walking outward along the sequence, not at write time by graph construction.
Building trajectories with a binary classifier
Knowing you want trajectories doesn't tell you how to find them. Where does one topic end and the next begin?
There's a deeper reason to use trajectories as the grouping unit, beyond "they're the simplest shape": they exploit the natural time-ordering of conversation. Every EDU has a position in the original transcript. That makes "find the topic boundaries" a 1D problem — walk the sequence and decide, at each adjacent pair, whether the topic continued or shifted. No clustering, no entity linking, no graph partitioning algorithm. Pairwise binary decisions over time-ordered atoms is enough. The 1D structure of conversation hands you the algorithm for free.
With the algorithm framed as 1D, the practical question is how to draw the boundaries. The first thing I tried was the obvious thing: hand the model a session and ask it to "decompose this into trajectories with EDUs." Single LLM call, structured JSON output. It looked clean.
It hallucinated. Given a long enough chunk, the model would invent turn ranges that didn't exist, fabricate summaries for turns it had never seen, and claim trajectory boundaries at positions outside the input. The mode of failure was always the same: a model asked to do both extraction and segmentation in one pass over-confidently filled in the gaps.
So the pipeline got split into three tightly-bounded calls:
Stage 1: Extract EDUs from a chunk of turns (Sonnet)
- Hard-bounded: source_turn_ids must be in range
- Output: list of atomic facts with provenance
Stage 2: Classify same-topic for each adjacent EDU (Haiku, sliding window)
- Binary: {"same_topic": true | false}
- Cannot hallucinate structure — output is one bit
Stage 3: Label each contiguous group as a trajectory (Sonnet)
- Input: a group of co-topic EDUs
- Output: 1-line summary + 2-5 keywords
Stage 2 is where the topic boundaries emerge. The classifier sees a small sliding window of EDUs centered on a candidate pair: the PREVIOUS EDU, the CANDIDATE EDU, plus a few neighbors as context. It answers one question — "does the candidate continue the previous's topic?" — and emits one bit.
A few design choices in stage 2 that matter more than they look:
- Provenance is a strong signal. If two EDUs come from the same turn, or from immediately adjacent turns, they almost certainly share a topic. The classifier prompt tells the model this explicitly. A single long assistant turn covers one thing in depth, not a dozen unrelated ones.
- Default-to-true on failure. When the classifier returns garbage or the call errors, the system assumes "same topic." Conservatively under-segmenting is fine — a slightly long trajectory still works at retrieval time. Over-segmenting fragments the chapter and loses surrounding context.
- Haiku, not Sonnet. It's a single-bit decision. Spending Sonnet tokens on it would buy nothing.
Once you have N-1 boolean decisions for N EDUs, segmentation is a one-liner: walk the sequence, start a new group whenever you hit a false. Stage 3 then labels each group with its summary and keywords.
The decomposition is the same lesson as the EDU step: when an LLM call has too many degrees of freedom, it invents. Constrain the surface area of each call until the model can't go wrong, and chain the bounded calls together.
Cross-trajectory structure: tags, not graphs
Within-session grouping gives you trajectories. The separate question is how trajectories connect to each other — how the system supports queries like "all the work I've done on pipewire," across many sessions and topics.
The textbook answer is a knowledge graph: nodes for entities, weighted edges for relationships, PageRank or similar for traversal. Academic memory papers love this and the math is satisfying.
But the graph structure that ships and gets used in production systems is, almost always, tags. Stack Overflow tags. GitHub topics. Gmail labels. Linear labels. Two items share a tag → they're connected. Two tags co-occur on items → they're connected. The graph structure is implicit, searchable, filterable, and trivial to maintain. It's been proven, repeatedly, to work at scale.
We lean on the same pattern: each trajectory carries 2-5 keywords, and that's the entire cross-trajectory layer. No nodes, no edges, no traversal algorithm. A keyword query is a SQL IN clause; a "what topics does this connect to" question is a co-occurrence count. Both are fast, both are obvious, and both work without special infrastructure.
Combining both choices: time-ordered trajectories give you the within-session structure, keyword tags give you the across-session structure. The trade-off is breadth — a trajectory hit returns the whole sub-conversation plus its neighbors (tens of kilobytes per hit), and a keyword hit can match dozens of trajectories. That's a big aperture. We accept the volume and claw it back at the filter stage, which is the next layer.
Querying: vectors, recency, and wide-then-filter
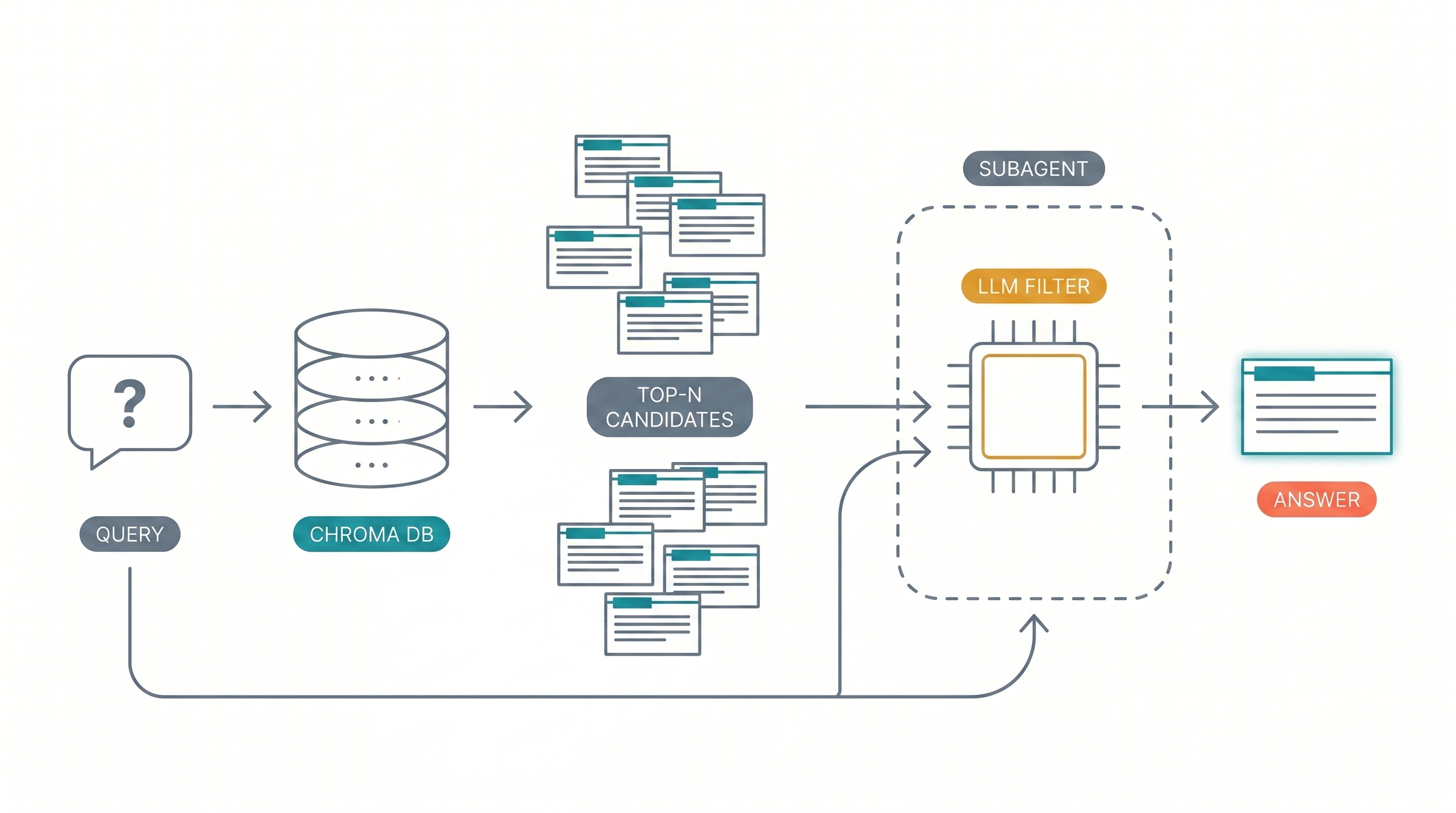
So now you have a project's worth of EDUs, organized into coherent trajectories and labeled with summaries and keywords. How do you retrieve relevant ones for a given question?
The base layer is vanilla RAG: embed the EDU text with a local model (nomic-embed-text-v1.5, 768d) and store it in a vector index (ChromaDB). At query time, embed the query and pull the top-N neighbors by cosine similarity.
Two adjustments turn this from "okay" into "good":
Recency bias. Conversation memory has a stronger recency effect than general knowledge. If you and the agent talked about pipewire six months ago and again last week, the more recent discussion is more likely to be what you mean. The fix is a soft exponential decay applied to similarity scores:
final_score = similarity * exp(-α * days_ago)
with α small (≈0.005-0.02). Recent facts get a mild boost, old facts get a mild penalty, and a highly relevant old fact still surfaces — it has to clear a slightly higher bar but it can. This is intentional: a recency cutoff would silently lose information; a recency decay just reorders.
Wide-then-filter. The single biggest finding from the EMem ablation was that the LLM relevance filter — running the top-50 candidates through a small model and asking it to keep the relevant ones — provided more accuracy gain than any other component, especially for multi-hop queries. The intuition: vector similarity is a coarse signal. It pulls in plenty of plausibly-relevant candidates, but you want a model in the loop to do the actual judging.
The pattern matters more than the specific implementation. Cast a wide net (50-100 candidates), then let an LLM prune. False positives are cheap (the filter ignores them); false negatives are expensive (you've lost information). The filter prompt is a one-liner: "be maximally inclusive — prefer false positives over missing relevant info."
In claude-memory this filter step is implemented as a subagent. Claude Code's Agent / Task tool dispatches a fresh sub-context with its own window. The subagent calls the retrieval MCP tool, reads the wall of candidate trajectories (often 50-100kb of stitched sub-conversations and their lead-in/lead-out neighbors), synthesizes a focused answer, and returns ~200-500 tokens of prose to the main agent. The wall never lands in the main context.
This solves a real problem: if the main agent reads the wall directly, every retrieval pollutes the conversation context with kilobytes of EDUs. Dispatching to a subagent gives you context isolation for free, with a single tool call. The MCP tool description is engineered to insist the calling agent dispatch via Agent rather than calling it inline:
"Returns memory excerpts as a wall-of-text. Always call this from inside an Agent/Task subagent, not from the main context — the wall can be 50–100kb and will bloat your context if you read it directly."
The index: a keyword cloud as a handle
Retrieval is the drill-down. But you also need an index — something the model sees at session start that orients it to what's available without dumping detail.
claude-memory builds a per-project index file at ingest time, capped at ~600 tokens, injected via a SessionStart hook. The structure:
## Preferences
- (EDUs tagged PREFERENCE — the user's stable communication and workflow choices)
## Recent Activity
- [2026-04-21] Reworked memory architecture around trajectories + subagent retrieval
- [2026-04-20] Benchmarked model comparison for EDU extraction
- ...
## Key Decisions / Gotchas
- [decision] ChromaDB HTTP client-server over in-process — avoids SQLite lock contention
- [gotcha] If PipeWire is updated via apt, the custom-built LV2 module needs rebuilding
- ...
## Keyword Cloud
chromadb, claude-memory, edu, extractor, ingestion, mcp, memory-index,
opus, pipewire, ranking, retrieval, sessionstart, subagent, trajectory
Three things are doing work here, and the keyword cloud is the most important.
The cloud is a handle. It's not retrieval; it's a signal that retrieval is worth trying. When the user asks about something, the model can scan the cloud for a hit — if pipewire is in the cloud and the user is asking about audio config, the model knows there's relevant memory and can call the recall tool with confidence. If nothing in the cloud is close, the model can skip retrieval and save the round-trip.
This is the cheapest possible "do you have anything on X?" check. A few hundred lowercase tokens, alphabetized, deterministic. Prompt-cache friendly because it's byte-stable when nothing changes.
The cloud is also where keyword normalization pays off. Every trajectory gets keywords from a stage-3 LLM call, and the labeler is told to prefer existing keywords from the project's cloud over inventing new ones. New keywords go through a similarity check against the existing cloud — if it's within 0.9 cosine of an existing canonical form, it auto-merges. This keeps the cloud from drifting into pipewire, PipeWire, pipewire-1.0, pipe-wire, etc.
The other sections are use-case specific:
- Recent Activity is just the most recent N trajectory summaries — a "what were we working on?" dashboard.
- Key Decisions / Gotchas ranks EDUs tagged
decisionorgotchabykeyword_frequency × recency_weight. Topics that recur across many trajectories are likely load-bearing; topics from last week are more relevant than topics from last quarter. - Preferences is just the EDUs the system saw the user state explicitly — "casual, not corporate", "process management one step at a time", and so on.
You could imagine other sections for other use cases: an open-questions list, an active-task tracker, a list of files the user has been editing. The pattern stays the same: cheap, deterministic, cache-friendly, and small enough to inject every session without taxing the context window.
The shape that emerges
Stack the layers and you get a clean separation of concerns:
| Layer | What it does | Why it's there |
| EDU extraction | Decompose conversations into atomic facts | EMem: 97% token reduction, beats full-context |
| Trajectory segmentation | Group co-topic EDUs via binary classifier | Preserve surrounding context at retrieval time |
| Vector store + recency | Coarse top-N retrieval, mild recency bias | Cheap candidate generation; recent facts win ties |
| LLM filter (subagent) | Prune candidates to the genuinely relevant | EMem: single largest accuracy gain, isolates context |
| Index (keyword cloud) | Orient the model at session start | Cheap signal that retrieval is available and worth trying |
None of the layers is exotic. Each one comes out of a paper finding or an observed failure mode. The interesting thing isn't any single layer — it's that they compose into a system with two distinct modes: a small always-on index (hundreds of tokens, injected at session start) and a deep retrieval path (invoked on demand, isolated in a subagent so the wall of candidate text never touches the main context).
If you take one thing from all this: the win in agent memory isn't the storage, it's the decomposition. EDUs make everything downstream cheap. Trajectories make EDUs interpretable. The keyword cloud makes the whole system visible to the model so it knows when to ask. Get those three right and the rest is plumbing.
claude-memory is open-source. It's not in the main Claude plugin marketplace yet — install it from the personal marketplace:
claude plugin marketplace add DuaneNielsen/claude-memory
claude plugin install claude-memory@duane-claude-plugins
Source, papers, and architecture notes are at github.com/DuaneNielsen/claude-memory.