Why Reward Shaping Sucks and What You Can Do About It

In my previous article on reward shaping, I walked through four hard-learned lessons about balancing collision penalties in a navigation task. I eventually found the "Goldilocks solution" - a -0.1 penalty that let my agent learn to navigate obstacles. Problem solved, right?
Well, not quite. I kept staring at this chart showing my agent was still colliding with objects way more than I'd like:
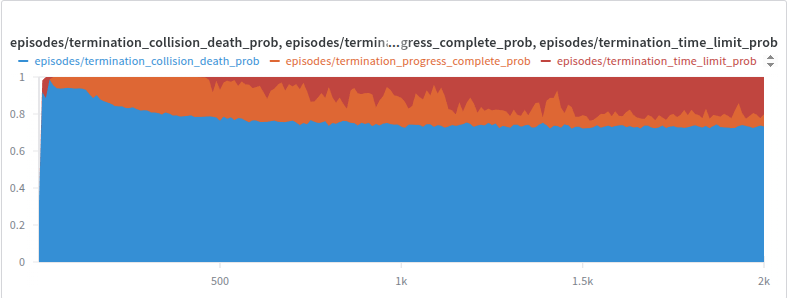
The bar shows that agents were only successfully navigating the course about 10% of the time, with collision being the primary cause of episode termination. My first instinct? Time for another reward shaping parameter sweep! Let's optimize that collision penalty some more...
But then I had a better idea. What if I stopped fighting against reinforcement learning and started leveraging its actual superpower?
The Reward Shaping Trap
Here's the thing about reward shaping: every time you add a shaped reward, you're making an assumption about what good behavior looks like. You're essentially saying "I know better than the Bellman equation." And maybe you do! But you're also:
- Adding parameters to tune - More knobs means more ways for things to go wrong
- Creating unpredictable side effects - That collision penalty might stop wall-running, but it might also stop the agent from ever getting close to walls, even when that's optimal
- Fighting against RL's core strength - The ability to learn implicit objectives through value function approximation
Rich Sutton put it perfectly in "The Bitter Lesson":
"The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin... We should stop trying to find ways to exploit our limited domain knowledge, and instead focus on discovering the general principles that will enable our methods to make use of the massive amounts of computation that will be available."
Every shaped reward is us trying to inject our "limited domain knowledge" instead of letting the algorithm figure it out through computation.
The "Optimize the Thing" Approach
So here's a radical idea: what if we just... optimized the thing we actually want to optimize? ᾒF
Let's think about it. Collision avoidance isn't really our goal - it's an implicit constraint. Our actual goal is "navigate through the obstacle course successfully." So let's give a reward of +1 when the agent reaches the goal, and 0 otherwise.
"But wait," you might say, "won't the agent just crash into everything?"
Here's where the Bellman equation becomes magical.
The Bellman Equation's Implicit Learning Magic
The Bellman equation is:
V(s) = max_a [R(s,a) + γ * V(s')]
This simple equation has a superpower: it propagates value backwards through time. When an agent reaches the goal and gets that +1 reward, the value function learns that all the states leading up to that success were valuable too.
But here's the key insight: episodes where the agent crashes get no reward. So through the magic of temporal difference learning, the value function automatically learns that:
- States just before crashes have low value
- Actions that lead to crashes have low value
- Collision avoidance emerges as an implicit behavior
The agent doesn't need us to explicitly tell it "don't hit walls." It figures out that wall-hitting episodes don't lead to rewards, so it learns to avoid them naturally.
This is reinforcement learning at its purest - the algorithm discovering optimal behavior through environmental feedback rather than human-designed reward signals.
The Exploration Challenge (And Its Solution)
"Okay sure," you might think, "but how will the agent ever explore enough to find the goal and get that +1 signal?"
This is the classic sparse reward problem. With a fixed spawn point, the agent would need to randomly stumble to the goal before learning anything useful. That could take... a while.
The solution is beautifully simple: random initialization of agent position.
Let's look at exploration patterns around a fixed spawn point:

The agent can only explore a tiny bubble around its starting position before crashing. Most episodes end with no reward signal.
Now let's see what happens with random spawn positions:
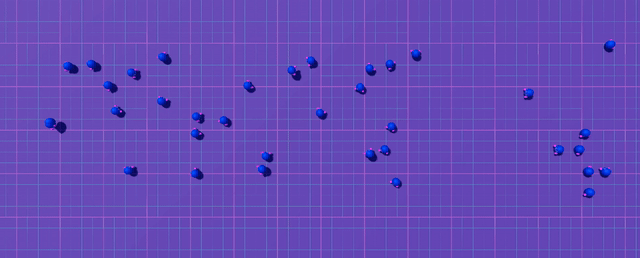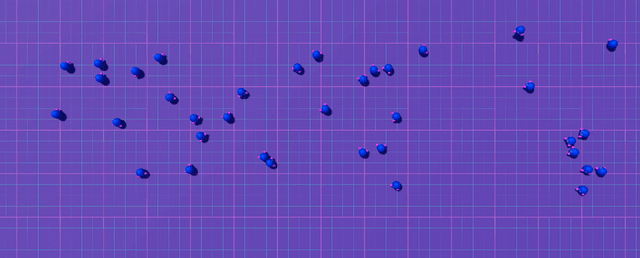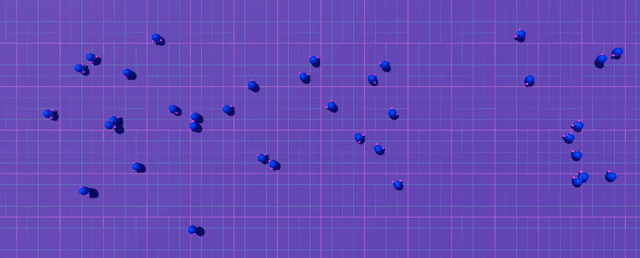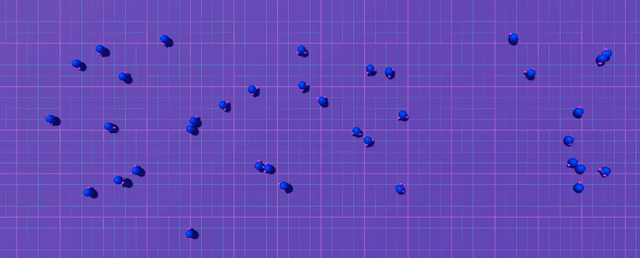
By randomizing the start position across our 4096 parallel simulations (thanks, Madrona engine!), we ensure some agents spawn close to the goal. These lucky agents provide immediate reward signal right from the start of training.
Some agents spawn near the goal and reach the edge of the map → immediate reward signal → learning begins → value function starts propagating back → collision avoidance emerges naturally.
The Results: Proof in the Pudding
After 1000 episodes of training with this approach:

And here's the real proof - the performance metrics we actually care about:
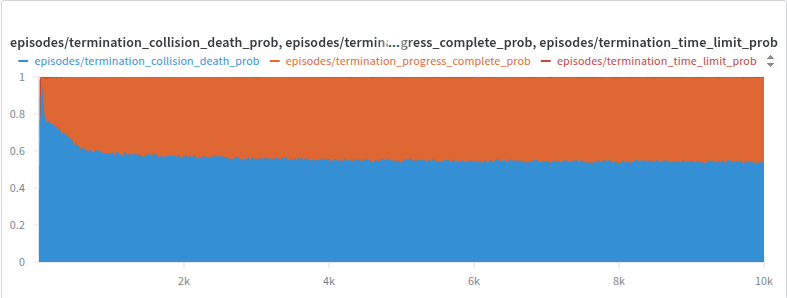
Look at that beautiful, steady increase in success rate! No parameter tuning, no reward engineering, no unpredictable side effects. Just clean, direct optimization of the thing we wanted to optimize all along.
When to "Optimize the Thing" Directly
This approach works best when:
- You can clearly define success - "Reach the goal" is unambiguous
- You have sufficient simulation capacity - Random initialization needs lots of parallel episodes
- The implicit constraints are learnable - Collision avoidance can be learned from episode outcomes
- You want robust, generalizable behavior - No hand-crafted biases to break in new environments
When reward shaping might still be necessary:
- Safety-critical applications where you can't afford exploration failures
- Environments where the implicit constraints are too complex to learn from sparse signals
- When you have strong domain knowledge about efficient learning paths
The Bitter Lesson Applied
My navigation problem perfectly illustrates Sutton's bitter lesson. I spent time crafting collision penalties, tuning magnitudes, trying curriculum learning - all attempts to inject my domain knowledge about "good navigation behavior."
The direct optimization approach said: "Forget your assumptions. Let computation and the Bellman equation figure it out."
And you know what? The algorithm found a better solution than my hand-crafted rewards ever did.
Sometimes to Optimize the Thing...
The best approach really is to optimize it.
Next time you catch yourself adding another shaped reward, ask: "Am I helping the algorithm or fighting against it?" Sometimes the most powerful thing you can do is get out of reinforcement learning's way and let it do what it does best - learn optimal behavior from environmental feedback.
Your agent might just surprise you with how good it gets when you stop micromanaging its learning process.
Interested in high-performance RL simulations like the one used in this article? Check out our Reality project - a simulation framework built on the Madrona engine that can run 4096+ parallel environments on a single GPU.
